Nosql, Python et mot de passe

L’actualité récente autour de la « soi-disant » compromission de comptes Google a remis goût du jour une thématique de R&D interne structurée autour de deux axes:
- L’analyse de la complexité d’un ensemble de mots de passe accumulé depuis plus de 10 ans,
- L’aggrégation des mots de passe afin de construire une base de connaissances basée sur l’utilisation statistique de mots de passe réellement utilisés.
Notre cahier des charges se composait des primitives suivantes:
- Accepter en entrée un fichier contenant un ensemble de mots de passe à analyser, structuré sous la forme d’un mot de passe par ligne encodé en latin-1 ou utf-8,
- Implémenter des mécanismes d’assainissement des entrées analysées afin de normaliser les dictionnaires des tests d’intrusion
- Intégrer l’extration d’une « copie » du fichier initial en fonction de leurs occurences,
- Réaliser une analyse de la complexité des différents mots de passe « unitaires » rencontrés dans les fichiers analysés: longueur, ensemble de caractères utilisés, nombre d’occurences,
Au cours de la phase de développement de PassMAID, nous nous sommes appuyé sur des listes de mots de passe disponibles publiquement, soit plus de 100 millions d’entrées.
Le « challenge » du projet PassMaid n’est pas induit par les opérations d’analyse d’un mot de passe réalisées en Python, mais réside au niveau du stockage des différentes entrées à la fois pour les opérations d’analyse, mais également pour la construction de la base de connaissances. La volumétrie importante des données à traiter et à stocker nous a orienté vers l’utilisation d’une base de données NoSQL.
Notre choix s’est porté aprés quelques évaluation sur la base de données Redis sous licence BSD. Cette technologie est particulièrement indiquée pour le stockage d’un grand nombre d’entrées de faible complexité notamment lorsque le principe de durabilité n’est pas requis: en effet, Redis maintient l’ensemble des données stockées en RAM (150 Mo par million d’entrées stockées). Cette caractéristique permet de ne pas introduire de différence notable entre les opérations de lecture et d’écriture tout en offrant de bonnes performances pour les opérations d’analyses.
Le fichier à analyser est lu ligne par ligne et des opérations d’assainissement sont réalisées sur chacune entrée récupérée, de manière à ne conserver que des données considérées comme valides. Si une entrée est considérée comme non-valide, car ayant été exclue par l’un des différents filtres activés, elle est ignorée. Dans le cas contraire, le mot de passe extrait est stocké en base puis est analysé.
Afin d’assurer la cohérence des données tout au long de l’analyse, chaque entrée est convertie en unicode, puis stockée en base en utilisant l’encodage UTF-8 car Redis n’accepte pas le stockage de chaînes de caractère au format unicode.
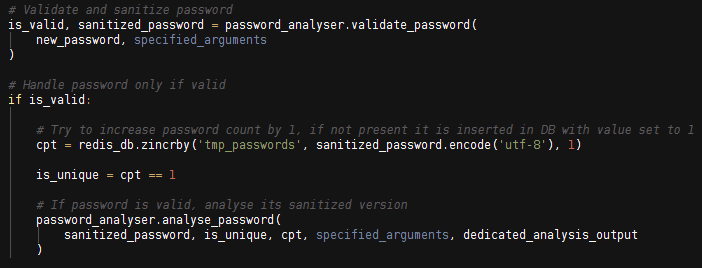
La sauvegarde du mot de passe est réalisée en utilisant deux objets de type « sorted set »: le premier pour le stockage des données temporaires relatives au fichier analysé, le second pour la gestion de la base de connaissances.
Ce type de données nous permet de représenter nativement l’association « mot de passe/ nombre d’occurences ». De plus, les primitives associées à ce type de données nous permettent de réaliser les opérations de classement des mots de passe avec un faible coût de traitement. Ainsi, une seule instruction « ZINCRBY » est nécessaire pour vérifier la présence d’un mot de passe en base et l’ajouter au besoin.
À ce jour, la capacité de stockage maximale pour la base de connaissances correspond au nombre maximal d’entrées pouvant être insérées dans un object de type « sorted set »: 2^32 – 1 éléments, soit plus de 4 milliards d’entrées uniques (4,294,967,295). Cette capacité peut être étendue en utilisant un nombre dynamique de « sorted sets »
Afin d’augmenter la rapidité d’analyse du fichier soumis en entrée, Redis offre la possibilité d’utiliser un « pipeline » afin de s’affranchir du RTT (Round Time Trip) entre deux requêtes réseau: le pipeline permet d’envoyer plusieurs requêtes à la base de données sans avoir à attendre les réponses, puis lit finalement l’ensemble des réponses.
Une seconde approche consiste à répartir l’exécution de l’analyse entre plusieurs processus grâce à l’utilisation du module Python « multiprocessing ».
Dans le cas d’une exécution « locale » où la même machine réalise l’analyse et le stockage des données, l’utilisation de plusieurs processus s’est révélée plus efficace que l’utilisation d’un pipeline. Cette solution nous offre un gain de plus de trois minutes sur l’analyse d’un fichier de type « RockYou ».
Les statistiques globales obtenues sont les suivantes:
[+] Global statistics ********************** [-] Total entries: 14,344,390 [-] Analyzed password entries: 14,331,467 [-] Excluded password entries: 12,923 [-] Unique passwords: 14,330,630
Le fichier «rockyou» analysé contient 14,344,390 entrées dont 12,923 ont été exclues par les différents filtres activés lors de l’exécution (configuration par défaut du script). Parmi les entrées non-exclues, 14,330,630 sont des entrées uniques, les entrées redondantes sont dues aux opérations d’assainissement du caractère anti-slash.
La répartition des entrées uniques en terme de longueur est la suivante:
[+] Password lengths (for unique entries)
*****************************************
[-] 1: 46 password(s) [ 00.0003 % ]
[-] 2: 339 password(s) [ 00.0024 % ]
[-] 3: 2,472 password(s) [ 00.0172 % ]
[-] 4: 18,099 password(s) [ 00.1263 % ]
[-] 5: 259,533 password(s) [ 01.8110 % ]
[-] 6: 1,948,796 password(s) [ 13.5988 % ]
[-] 7: 2,507,212 password(s) [ 17.4955 % ]
[-] 8: 2,966,487 password(s) [ 20.7003 % ]
[-] 9: 2,190,663 password(s) [ 15.2866 % ]
[-] 10: 2,012,917 password(s) [ 14.0463 % ]
...
...
Nous constatons donc que la grande majorité des mots de passe (environ 80%) ont une longueur comprise entre 6 et 10 caractères.
Les statistiques suivantes mettent en évidence la composition des différents mots de passe identifiés et les entrées les plus fréquement rencontrées au cours de l’analyse.
[*] Top 10 passwords
---------------------------------------------------
[-] \ 11 appearance(s)
[-] asdfghjkl;' 05 appearance(s)
[-] 1234567890-=\ 04 appearance(s)
[-] ojkiyd0y' 04 appearance(s)
[-] iydotgfHdF'j 04 appearance(s)
[-] J'ADENKHYA 04 appearance(s)
[-] iyd0y' 04 appearance(s)
[-] iydgmv0y' 04 appearance(s)
[-] ohv's,k 04 appearance(s)
[-] zhane' 03 appearance(s)
[*] Charset analysis (for unique entries)
------------------------------------------
[-] lowercase / numbers:
6,082,774 password(s) [ 42.4460 % ]
[-] lowercase:
3,771,685 password(s) [ 26.3190 % ]
[-] numbers:
2,347,074 password(s) [ 16.3780 % ]
[-] lowercase / ascii_special / numbers:
415,202 password(s) [ 02.8973 % ]
...
...
L’analyse de ces résultats nous indique que 40 % des mots de passes analysés se composent de lettres minuscules et de chiffres, 26 % uniquement de lettres minuscules et 16% de chiffres uniquement.
Notre outil PassMAID est gratuitement disponible, sur simple demande à outil@talsion.com pour toute personne ayant un motif légitime de l’utiliser et de le détenir afin de respecter l’article 323-3-1 du code pénal Français.